How to use Tesseract OCR in C# 2020.1 Details
Shareware 42.03 MB
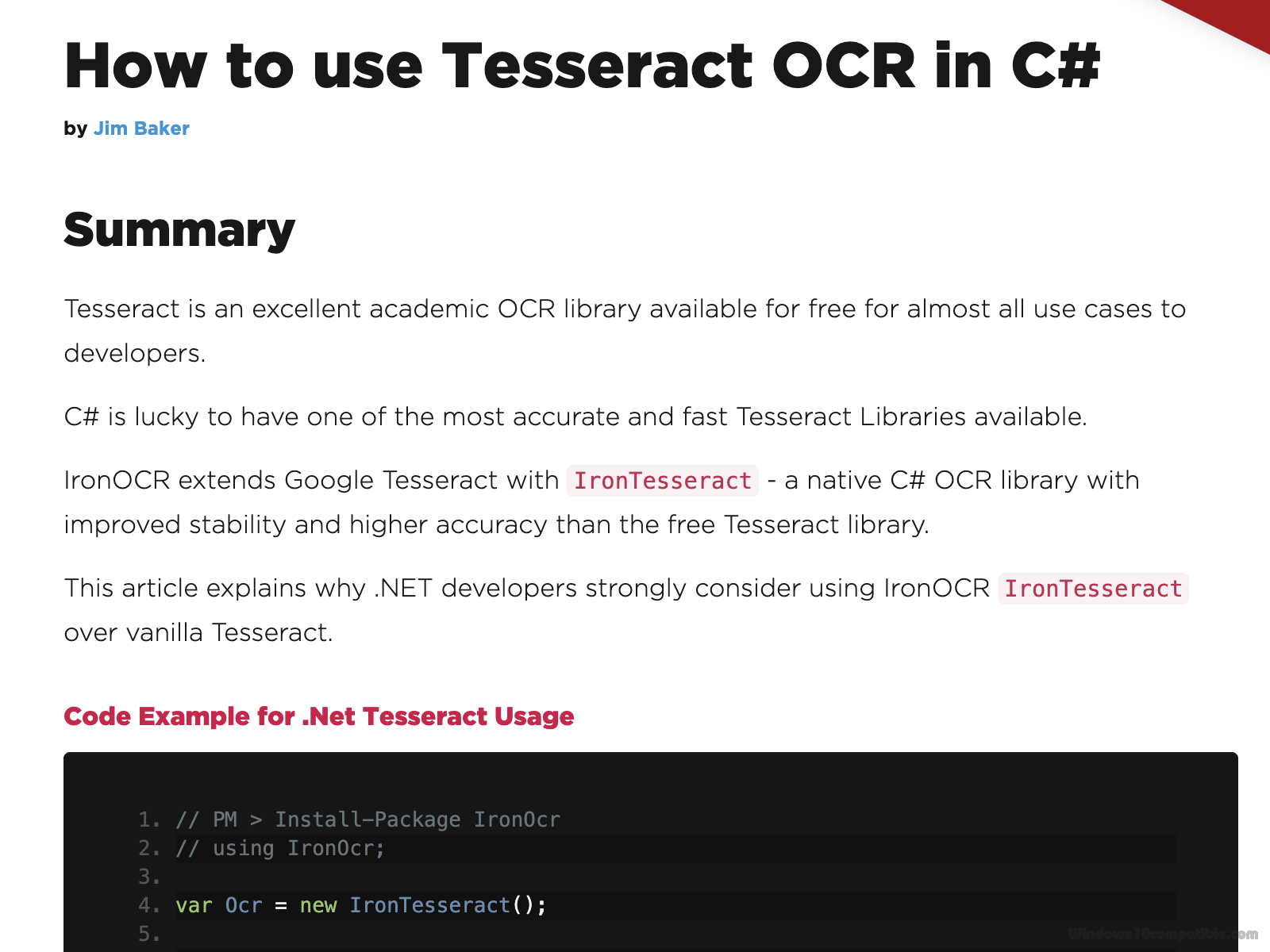
Iron OCR is an advanced OCR library for the .NET framework aimed at C# engineers. It provides a highly optimised Tesseract engine embedded within Iron OCR with nothing external to install. The Iron OCR Iron Tesseract class can then be used to read text from scanned images and PDF documents. Iron OCR allows us to read image files, such as TIFFs, JPGs, GIFs, & PNGs, in .NET using Tesseract. Iron OCR also provides PDF OCR technology using Tesseract.
Publisher Description
 Iron OCR can use the Tesseract 3, Tesseract 4, and Tesseract 5 engine. It provides these on Windows, Linux, and Mac operating systems, and everything you need is installed automatically when you install the Iron OCR NuGet package: https://www.nuget.org/packages/IronOcr/
Tesseract itself is a command line executable which may not be appropriate for using in real-world scenarios such as web applications. Iron OCR provides the latest Tesseract 5 technology directly to .NET developers without requiring them to install Tesseract onto their host operating system manually. We find that Iron OCR provides an advanced image sampling and upscaling technology, ensuring that even low quality scans get great results with Iron Tesseract: https://ironsoftware.com/csharp/ocr/tutorials/c-sharp-tesseract-ocr/
Iron OCR can be used in any type of .NET project. We find it is regularly popular in the development of server applications and desktop applications. We have also seen customers use it within web applications to scan uploaded content and turn it into text, which can then be purposed for another use, such as a database.
Iron OCR allows us to read image files, such as TIFFs, JPGs, GIFs, and PNGs, in .NET using Tesseract. Iron OCR (https://ironsoftware.com/csharp/ocr/) also provides PDF OCR technology using Tesseract within .NET applications.
You will be able to find code examples on the Iron Software website showing how to use Iron OCR as a Tesseract alternative for .NET and C# projects. It includes examples of PDF OCR using Tesseract in C#. Please also find information on licensing here: https://ironsoftware.com/csharp/ocr/licensing/
Iron OCR allows developers to treat PDFs as if they were scanned images and provides full functionality for PDF OCR. This includes not only reading PDFs and turning them back into plain text, but also producing PDFs. Iron OCR can use its Tesseract engine to create a search indexable PDF from a flat PDF or image-based contet.
Iron OCR can use the Tesseract 3, Tesseract 4, and Tesseract 5 engine. It provides these on Windows, Linux, and Mac operating systems, and everything you need is installed automatically when you install the Iron OCR NuGet package: https://www.nuget.org/packages/IronOcr/
Tesseract itself is a command line executable which may not be appropriate for using in real-world scenarios such as web applications. Iron OCR provides the latest Tesseract 5 technology directly to .NET developers without requiring them to install Tesseract onto their host operating system manually. We find that Iron OCR provides an advanced image sampling and upscaling technology, ensuring that even low quality scans get great results with Iron Tesseract: https://ironsoftware.com/csharp/ocr/tutorials/c-sharp-tesseract-ocr/
Iron OCR can be used in any type of .NET project. We find it is regularly popular in the development of server applications and desktop applications. We have also seen customers use it within web applications to scan uploaded content and turn it into text, which can then be purposed for another use, such as a database.
Iron OCR allows us to read image files, such as TIFFs, JPGs, GIFs, and PNGs, in .NET using Tesseract. Iron OCR (https://ironsoftware.com/csharp/ocr/) also provides PDF OCR technology using Tesseract within .NET applications.
You will be able to find code examples on the Iron Software website showing how to use Iron OCR as a Tesseract alternative for .NET and C# projects. It includes examples of PDF OCR using Tesseract in C#. Please also find information on licensing here: https://ironsoftware.com/csharp/ocr/licensing/
Iron OCR allows developers to treat PDFs as if they were scanned images and provides full functionality for PDF OCR. This includes not only reading PDFs and turning them back into plain text, but also producing PDFs. Iron OCR can use its Tesseract engine to create a search indexable PDF from a flat PDF or image-based contet.
Download and use it now: How to use Tesseract OCR in C#
Related Programs
Tesseract OCR in C#
What is C# Tesseract OCR . What is C# Tesseract OCR The Tesseract engine optical characters recognition (OCR), is a technology that converts scanned paper documents, PDF files and images into searchable text data. OCR engines detect the characters in...
- Shareware
- 06 Oct 2021
- 111.01 MB
Tesseract 5 C#
So many companies are moving to a digital system to document, track, and log all of their critical information. From inventory management in a new eCommerce-based shop out of a garage to an enterprise-level medical facility needing to transform patient...
- Shareware
- 06 Oct 2022
- 75.95 MB
Tesseract OCR Windows
Integrating barcode technology into a business is incredibly important given the current demands of digital record keeping and inventory management in the marketplace. With Tesseract OCR Windows by the team at IronSoftware, you can leverage this tech into your next...
- Shareware
- 15 Dec 2022
- 154.26 MB
Tesseract Rectangle
Tesseract Rectangle adds OCR to projects within the VB and .NET C# environment that fully supports .NET 5, Core, Standard, Framework, and Azure. This enables your next project build to integrate image and text reading using QR and barcode technology....
- Shareware
- 04 Aug 2022
- 191.28 MB
Tesseract OCR Speed
Scan old files with Tesseract OCR Speed and transform your company's inventory management and record keeping. This bespoke tool enhances your next project without the unnecessary additional resources from off-the-shelf software solutions. Instead of wasting time and money trying to...
- Shareware
- 04 Aug 2022
- 191.28 MB